浏览器渲染流程
解析 Parsing
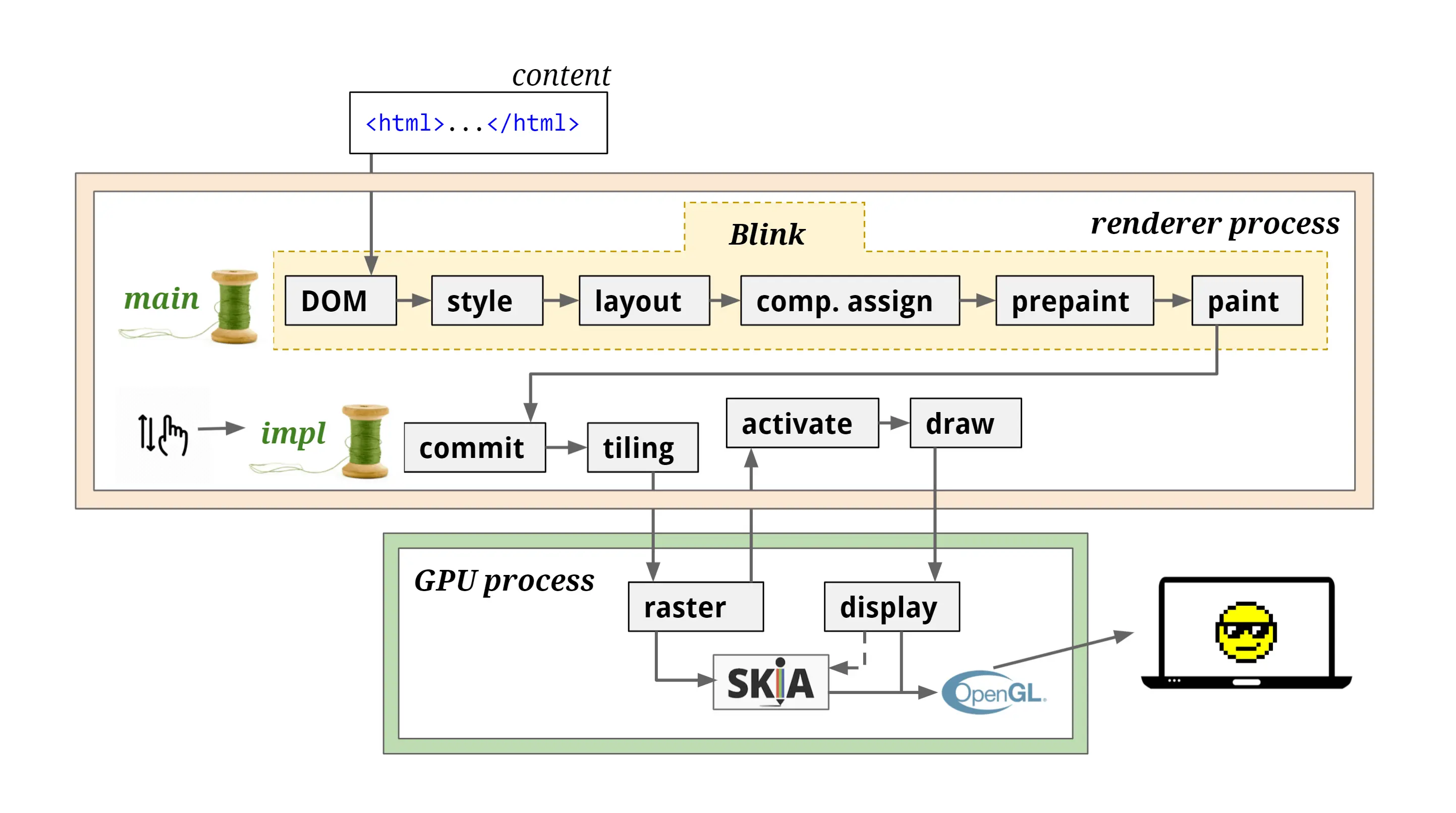
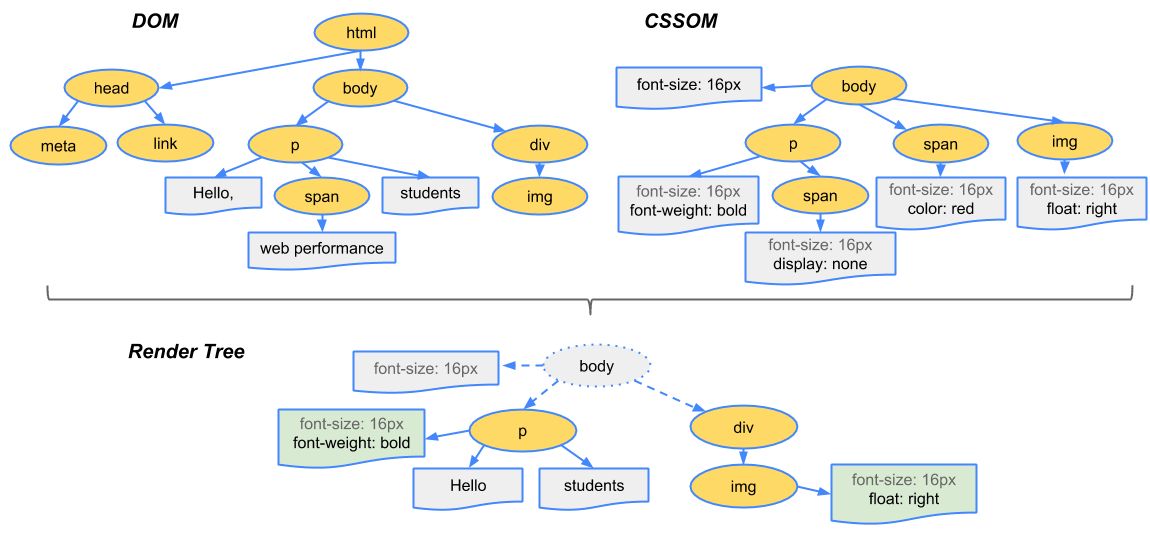
一旦浏览器收到数据的第一块,它就可以开始解析收到的信息。"解析"是浏览器将通过网络接收的数据转换为 DOM 和 CSSOM 的步骤,通过渲染器把 DOM 和 CSSOM 在屏幕上绘制成页面。
- DOM(Document Object Model——文档对象模型)是用来呈现以及与任意 HTML 或 XML 文档交互的 API。DOM 是载入到浏览器中的文档模型,以节点树的形式来表现文档,每个节点代表文档的构成部分(例如:页面元素、字符串或注释等等)。DOM 是万维网上使用最为广泛的 API 之一,因为它允许运行在浏览器中的代码访问文件中的节点并与之交互。节点可以被创建,移动或修改。事件监听器可以被添加到节点上并在给定事件发生时触发。
- CSS Object Model (CSSOM)。CSS 对象模型 (CSSOM) 是树形形式的所有 CSS 选择器和每个选择器的相关属性的映射,具有树的根节点,同级,后代,子级和其他关系。CSSOM 与 文档对象模型 (DOM) 非常相似。两者都是关键渲染路径的一部分,也是正确渲染一个网站必须采取的一系列步骤。
CSSOM 与 DOM 一起构建渲染树,浏览器依次使用渲染树来布局和绘制网页。
构建 DOM 树 Building the DOM tree
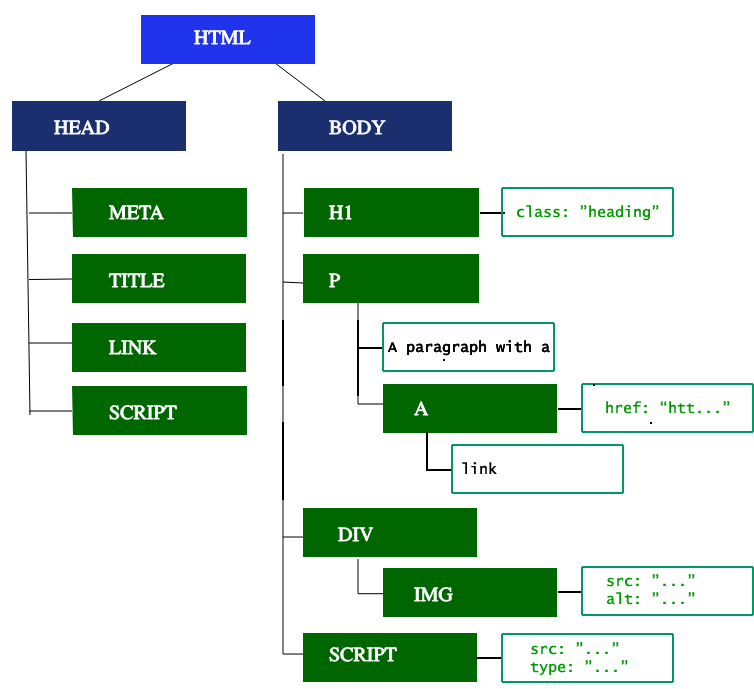
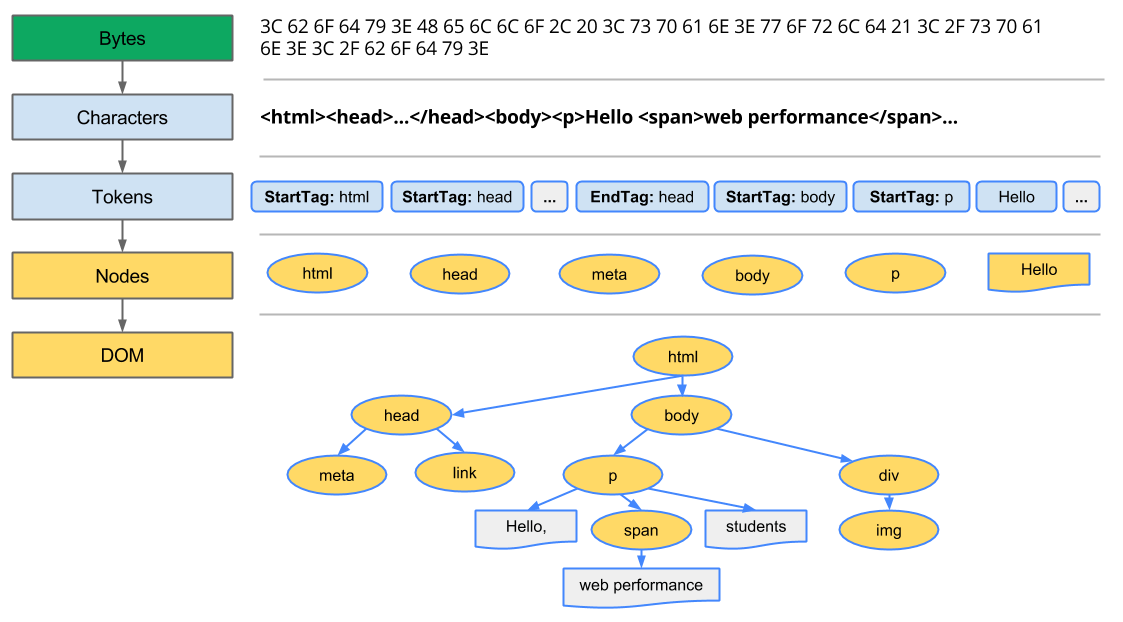
第一步是处理 HTML 标记并构造 DOM 树。HTML 解析涉及到 tokenization 和树的构造。HTML 标记包括开始和结束标记,以及属性名和值。如果文档格式良好,则解析它会简单而快速。解析器将标记化的输入解析到文档中,构建文档树。
DOM 树描述了文档的内容。<html> 元素是第一个标签也是文档树的根节点。树反映了不同标记之间的关系和层次结构。嵌套在其他标记中的标记是子节点。DOM 节点的数量越多,构建 DOM 树所需的时间就越长。
当解析器发现非阻塞资源,例如一张图片,浏览器会请求这些资源并且继续解析。当遇到一个 CSS 文件时,解析也可以继续进行,但是对于 <script> 标签(特别是没有 async 或者 defer 属性的)会阻塞渲染并停止 HTML 的解析。尽管浏览器的预加载扫描器加速了这个过程,但过多的脚本仍然是一个重要的瓶颈。
主线程解析 HTML 并构建出结构化的树状数据结构 DOM 树,需要经历以下几个步骤:
- Conversion(转换):浏览器从网络或磁盘读取 HTML 文件原始字节,根据指定的文件编码(如 UTF-8)将字节转换成字符。
- Tokenizing(分词):浏览器根据 HTML 规范将字符串转换为不同的标记(如
<html>,<body>)。 - Lexing(语法分析):上一步产生的标记将被转换为对象,这些对象包含了 HTML 语法的各种信息,如属性、属性值、文本等。
- DOM construction(DOM 构造):因为 HTML 标记定义了不同标签之间的关系,上一步产生的对象会链接在一个树状数据结构中,以标识父子、兄弟关系。
预加载扫描器 Preload scanner
浏览器构建 DOM 树时,这个过程占用了主线程。当这种情况发生时,预加载扫描仪将解析可用的内容并请求高优先级资源,如 CSS、JavaScript 和 web 字体。多亏了预加载扫描器,我们不必等到解析器找到对外部资源的引用来请求它。它将在后台检索资源,以便在主 HTML 解析器到达请求的资源时,它们可能已经在运行,或者已经被下载。预加载扫描仪提供的优化减少了阻塞。
<link rel="stylesheet" src="styles.css" />
<script src="myscript.js" async></script>
<img src="myimage.jpg" alt="image description" />
<script src="anotherscript.js" async></script>
在这个例子中,当主线程在解析 HTML 和 CSS 时,预加载扫描器将找到脚本和图像,并开始下载它们。为了确保脚本不会阻塞进程,当 JavaScript 解析和执行顺序不重要时,可以添加 async 属性或 defer 属性。
等待获取 CSS 不会阻塞 HTML 的解析或者下载,但是它确实会阻塞 JavaScript,因为 JavaScript 经常用于查询元素的 CSS 属性。
如果不想因 JS 阻塞 HTML 的解析,可以为 script 标签添加 defer 属性或将 script 放在 body 结束标签之前,浏览器会在最后执行 JS 代码,避免阻塞 DOM 构建。
构建 CSSOM 树 Building the CSSOM
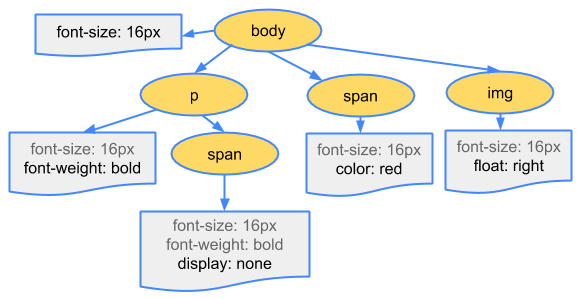
第二步是处理 CSS 并构建 CSSOM 树。CSS 对象模型和 DOM 是相似的。DOM 和 CSSOM 是两棵树。它们是独立的数据结构。浏览器将 CSS 规则转换为可以理解和使用的样式映射。浏览器遍历 CSS 中的每个规则集,根据 CSS 选择器创建具有父、子和兄弟关系的节点树。
与 HTML 一样,浏览器需要将接收到的 CSS 规则转换为可以使用的内容。因此,它重复了 HTML 到对象的过程,但对于 CSS。
CSSOM 树包括来自用户代理样式表的样式。浏览器从适用于节点的最通用规则开始,并通过应用更具体的规则递归地优化计算的样式。换句话说,它级联属性值。
构建 CSSOM 非常非常快,并且在当前的开发工具中没有以独特的颜色显示。相反,开发人员工具中的"重新计算样式"显示解析 CSS、构建 CSSOM 树和递归计算计算样式所需的总时间。在 web 性能优化方面,它是可轻易实现的,因为创建 CSSOM 的总时间通常小于一次 DNS 查询所需的时间。
JavaScript 编译 JavaScript Compilation
当 CSS 被解析并创建 CSSOM 时,其他资源,包括 JavaScript 文件正在下载(借助预加载扫描器)。JavaScript 被解释、编译、解析和执行。脚本被解析为抽象语法树。一些浏览器引擎使用抽象语法树并将其传递到解释器中,输出在主线程上执行的字节码。这就是所谓的 JavaScript 编译。
构建辅助功能树 Building the Accessibility Tree
浏览器还构建辅助设备用于分析和解释内容的辅助功能(accessibility)树。无障碍对象模型(AOM)类似于 DOM 的语义版本。当 DOM 更新时,浏览器会更新辅助功能树。辅助技术本身无法修改无障碍树。
在构建 AOM 之前,屏幕阅读器(screen readers)无法访问内容。
渲染 Render
渲染步骤包括样式、布局、绘制,在某些情况下还包括合成。在解析步骤中创建的 CSSOM 树和 DOM 树组合成一个 Render 树,然后用于计算每个可见元素的布局,然后将其绘制到屏幕上。在某些情况下,可以将内容提升到它们自己的层并进行合成,通过在 GPU 而不是 CPU 上绘制屏幕的一部分来提高性能,从而释放主线程。
样式 Style
第三步是将 DOM 和 CSSOM 组合成一个 Render 树,计算样式树或渲染树从 DOM 树的根开始构建,遍历每个可见节点。
像 <head> 和它的子节点以及任何具有 display: none 样式的结点,例如 script { display: none; }(在 user agent stylesheets 可以看到这个样式)这些标签将不会显示,也就是它们不会出现在 Render 树上。具有 visibility: hidden 的节点会出现在 Render 树上,因为它们会占用空间。由于我们没有给出任何指令来覆盖用户代理的默认值,因此上面代码示例中的 script 节点将不会包含在 Render 树中。
每个可见节点都应用了其 CSSOM 规则。Render 树保存所有具有内容和计算样式的可见节点——将所有相关样式匹配到 DOM 树中的每个可见节点,并根据 CSS 级联确定每个节点的计算样式。
为了构建 Render 树,浏览器主要完成了下列工作:
- 从 DOM 树的根节点开始遍历每个可见节点。
- 某些不可见节点(例如 script、head、meta 等),它们不会体现在渲染输出中,会被忽略。
- 某些通过设置 display 为 none 隐藏的节点,在渲染树中也会被忽略。
- 为伪元素创建 LayoutObject。
- 为行内元素创建匿名包含块对应的 LayoutObject。
- 对于每个可见节点,为其找到适配的 CSSOM 规则并应用它们。
- 产出可见节点,包含其内容和计算的样式。
布局 Layout
第四步是在渲染树上运行布局以计算每个节点的几何体。布局是确定呈现树中所有节点的宽度、高度和位置,以及确定页面上每个对象的大小和位置的过程。回流是对页面的任何部分或整个文档的任何后续大小和位置的确定。
构建渲染树后,开始布局。渲染树标识显示哪些节点(即使不可见)及其计算样式,但不标识每个节点的尺寸或位置。为了确定每个对象的确切大小和位置,浏览器从渲染树的根开始遍历它。
在网页上,大多数东西都是一个盒子。不同的设备和不同的桌面意味着无限数量的不同的视区大小。在此阶段,考虑到视区大小,浏览器将确定屏幕上所有不同框的尺寸。以视区的大小为基础,布局通常从 body 开始,用每个元素的框模型属性排列所有 body 的子孙元素的尺寸,为不知道其尺寸的替换元素(例如图像)提供占位符空间。
第一次确定节点的大小和位置称为布局。随后对节点大小和位置的重新计算称为回流。在我们的示例中,假设初始布局发生在返回图像之前。由于我们没有声明图像的大小,因此一旦知道图像大小,就会有回流。
浏览器的布局计算工作包含以下内容:
- 根据 CSS 盒模型及视觉格式化模型,计算每个元素的各种生成盒的大小和位置。
- 计算块级元素、行内元素、浮动元素、各种定位元素的大小和位置。
- 计算文字,滚动区域的大小和位置。
- LayoutObject 有两种类型:
- 传统的 LayoutObject 节点,会把布局运算的结果重新写回布局树中。
- LayoutNG(Chrome 76 开始启用)节点的输出是不可变的,会保存在 NGLayoutResult 中,这是一个树状的结构,相比之前的 LayoutObject,少了很大回溯计算,提高了性能。
绘制 Paint
最后一步是将各个节点绘制到屏幕上,第一次出现的节点称为 first meaningful paint。在绘制或光栅化阶段,浏览器将在布局阶段计算的每个框转换为屏幕上的实际像素。绘画包括将元素的每个可视部分绘制到屏幕上,包括文本、颜色、边框、阴影和替换的元素(如按钮和图像)。浏览器需要非常快地完成这项工作。
为了确保平滑滚动和动画,占据主线程的所有内容,包括计算样式,以及回流和绘制,必须让浏览器在 16.67 毫秒内完成。在 2048x1536 分辨率的 iPad 上,有超过 314.5 万像素将被绘制到屏幕上。那是很多像素需要快速绘制。为了确保重绘的速度比初始绘制的速度更快,屏幕上的绘图通常被分解成数层。如果发生这种情况,则需要进行合成。
绘制可以将布局树中的元素分解为多个层。将内容提升到 GPU 上的层(而不是 CPU 上的主线程)可以提高绘制和重新绘制性能。有一些特定的属性和元素可以实例化一个层,包括 <video> 和 <canvas>,任何 CSS 属性为 opacity、3D transform、will-change 的元素,还有一些其他元素。这些节点将与子节点一起绘制到它们自己的层上,除非子节点由于上述一个(或多个)原因需要自己的层。
分层确实可以提高性能,但是它以内存管理为代价,因此不应作为 web 性能优化策略的一部分过度使用。
Paint 阶段将 LayoutObject 树转换成供合成器使用的高效渲染格式,包括一个包含 display item 列表的 cc::Layers 列表,与该列表与 cc::PropertyTrees 关联。
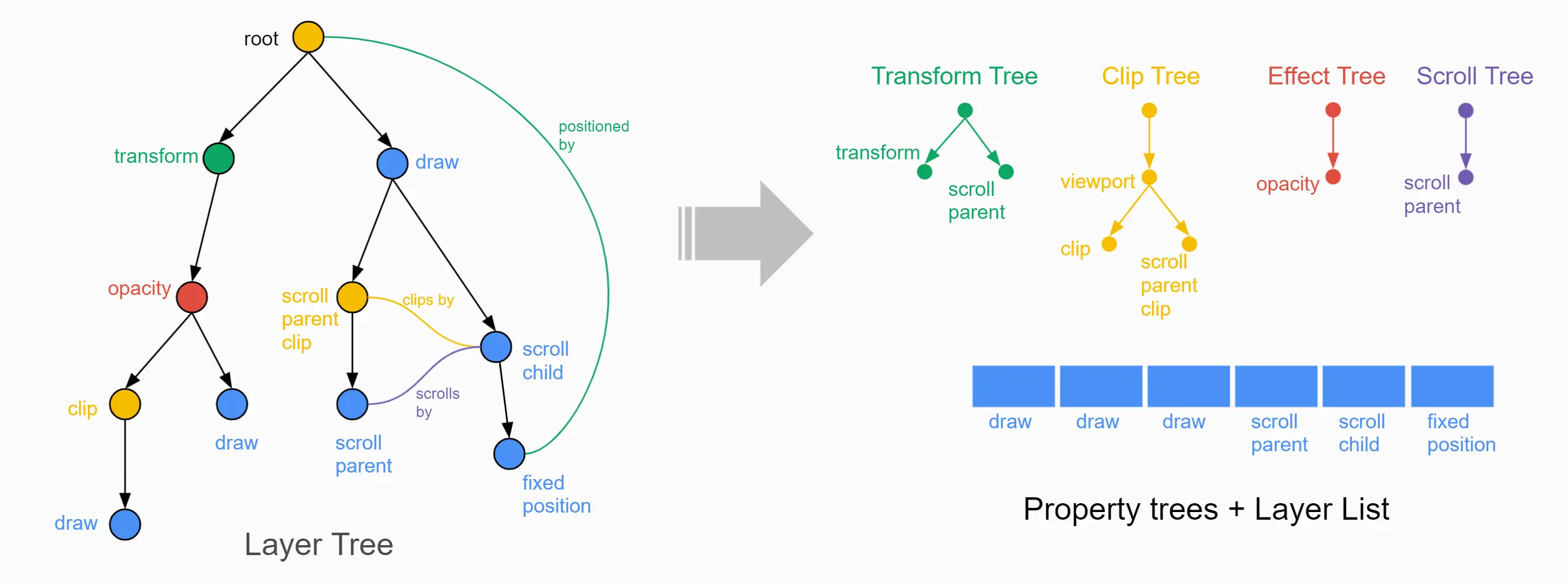
构建 PaintLayer RenderLayer 树
构建完成的 LayoutObject 树还不能拿去显示,因为它不包含绘制的顺序(z-index)。同时,也为了考虑一些复杂的情况,如 3D 变换、页面滚动等,浏览器会对上一步的节点进行分层处理。这个处理过程被称为建立层叠上下文。
浏览器会根据 CSS 层叠上下文规范,建立层叠上下文,常见情况如下:
- DOM 树的 Document 节点对应的 RenderView 节点。
- DOM 树中 Document 节点的子节点,也就是 HTML 节点对应的 RenderBlock 节点。
- 显式指定 CSS 位置的节点(position 为 absolute 或者 fixed)。
- 具有透明效果的节点。
- 具有 CSS 3D 属性的节点。
- 使用 Canvas 元素或者 Video 元素的节点。
浏览器遍历 LayoutObject 树的时候,建立了 PaintLayer 树,LayoutObject 与 PaintLayer 也不一定是一一对应的。每个 LayoutObject 要么与自己的 PaintLayer 关联,要么与拥有 PaintLayer 的第一个祖先的 PaintLayer 关联。
构建 cc::Layer 与 display items
浏览器会继续根据 PaintLayer 树创建 cc::Layer 列表。cc::Layer 是列表状结构,每个 layer 包含了个 DisplayItem 列表,每个 DisplayItem 包含了实际的 paint op 指令。将页面分层,可以让一个图层独立于其他的图层进行变换和光栅化处理。
- 合成更新(Compositing update)
- 依据 PaintLayer 决定分层(GraphicsLayers)
- 这个策略被称为 CompositeBeforePaint,未来会被 CompositeAfterPaint 替代。
- PrePaint
- PaintInvalidator 进行失效检查,找出需要绘制的 display items。
- 构建 paint property 树,该树能使动画、页面滚动,clip 等变化仅在合成线程运行,提高性能。
- Paint
- 遍历 LayoutObject 树并创建 display items 列表。
- 为共享同样 property tree 状态的 display items 列表创建 paint chunks 分组。
- 将结果 commit 到 compositor。
- CompositeAfterPaint 将在此时决定分层。
- 将 paint chunks 通过 cc::Layer 列表传递给 compositor。
- 将 property 树转换为 cc::PropertyTrees。
上面的流程中,有两个不同的创建合成层的时机,一个是 paint 之前的 CompositeBeforePaint,该操作在渲染主线程中完成。一个是 paint 之后的 CompositeAfterPaint,后续创建 layer 的操作在 CC(Chromium Compositor)线程中完成。
合成 Compositing
当文档的各个部分以不同的层绘制,相互重叠时,必须进行合成,以确保它们以正确的顺序绘制到屏幕上,并正确显示内容。
当页面继续加载资源时,可能会发生回流(回想一下我们迟到的示例图像),回流会触发重新绘制和重新组合。如果我们定义了图像的大小,就不需要重新绘制,只需要重新绘制需要重新绘制的层,并在必要时进行合成。但我们没有包括图像大小!从服务器获取图像后,渲染过程将返回到布局步骤并从那里重新开始。
合成阶段在 CC(Chromium Compositor)线程中进行。
commit
当 Paint 阶段完成后,主线程进入 commit 阶段,将 cc::Layer 中的 layer list 和 property 树更新到 CC 线程的 LayerImpl 中,commit 完成。commit 进行的过程中,主线程被阻塞。
tiling & raster
raster(光栅化)是将 display item 中的绘制操作转换为位图的过程。
光栅化的主要操作流程如下:
- tiling:将 layer 分成 tiles(图块)。因为有的 layer 可能很大(如整个文档的滚动根节点),对整层的光栅化操作代价昂贵,且 layer 中有的部分是不可见的,会造成不必要的浪费。
- tiles 是光栅化的基本单元。光栅化操作是通过光栅线程池处理的。离视口更近的 tiles 具有更高的优先级,将优先处理。
- 一个 layer 实际上会生成多种分辨率的 tiles。
- raster 同样也会处理页面引用的图片资源,display items 中的 paint ops 引用了这些压缩数据,raster 会调用合适的解码器来解压这些数据。
- raster 会通过 Skia 来进行 OpenGL 调用,光栅化数据。
- 渲染进程是运行在沙箱中的,不能直接进行系统调用。paint ops 通过 IPC(MOJO)传递给 GPU 进程,GPU 进程会执行真实的 OpenGL(为了保证性能,在 Windows 上转为 DirectX)调用。
- 光栅化的位图结果保存在 GPU 内存中,通常作为 OpenGL 材质对象保存。
- 双缓冲机制:主线程随时会有 commit 到来,当前的光栅化行为在 pending tree(LayerImpl)上进行,一旦光栅化操作完成,将 pending tree 变为 active tree,后续的 draw 操作在 active tree 上进行。
draw
当所有的 tiles 都完成光栅化后,会生成 draw quads(绘制四边形)。每个 draw quads 是包含一个在屏幕特定位置绘制 tile 的命令,该命令同时考虑了所有应用到 layer tree 的变换。每个四边形引用了内存中 tile 的光栅化输出。四边形被包裹在合成帧对象(compositor frame object)中,然后提交(submit)到浏览器进程。
display compositor(viz,visual 的简称)
viz 位于 GPU 进程中,viz 接收来自浏览器的合成帧,合成帧来自多个渲染进程,以及浏览器自身 UI 的 compositor。
合成帧和屏幕上将要绘制的位置关联,该位置叫做 surface。surface 可以嵌套其他 surface,浏览器 UI 的 surface 嵌套了渲染进程的 surface,渲染进程的 surface 嵌套了其他跨域 iframes(同源的 iframe 共享相同的渲染进程)的 surface。viz 同步传入的帧,并处理嵌套 surfaces 的依赖(surface aggregation)。
最终的显示流程:
- viz 会发出 OpenGL 调用将合成帧中的 quads 发送到 GPU 线程的 backbuffer 中。
- 在新的模式中,viz 会使用 Skia 代替原始 OpenGL 调用。
- 在大部分平台上,viz 的输出也是双缓冲结构,draw 首先到达 backbuffer,通过 swapping 操作转换成 frontbuffer 最终显示在屏幕上。
总结
浏览器渲染流程
一般所有的浏览器都会经过五大步骤,分别是:
- Parse:一旦浏览器收到数据的第一块,它就可以开始解析收到的信息。"解析"是浏览器将通过网络接收的数据转换为 DOM 和 CSSOM 的步骤。
- Building the DOM tree:处理 HTML 标记并构造 DOM 树。
- Building the CSSOM:处理 CSS 并构建 CSSOM 树。
- Style:将 DOM 和 CSSOM 组合成一个 Render 树,计算样式树或渲染树从 DOM 树的根开始构建,遍历每个可见节点。
- Layout:在渲染树上运行布局以计算每个节点的几何体。布局是确定呈现树中所有节点的宽度、高度和位置,以及确定页面上每个对象的大小和位置的过程。回流是对页面的任何部分或整个文档的任何后续大小和位置的确定。第一次确定节点的大小和位置称为布局。随后对节点大小和位置的重新计算称为回流。
- Paint:将各个节点绘制到屏幕上,包括将元素的每个可视部分绘制到屏幕上,包括文本、颜色、边框、阴影和替换的元素(如按钮和图像)。
- 绘制可以将布局树中的元素分解为多个层。将内容提升到 GPU 上的层(而不是 CPU 上的主线程)可以提高绘制和重新绘制性能。
- 分层确实可以提高性能,但是它以内存管理为代价,因此不应作为 web 性能优化策略的一部分过度使用。
- Composite:当文档的各个部分以不同的层绘制,相互重叠时,必须进行合成,以确保它们以正确的顺序绘制到屏幕上,并正确显示内容。
浏览器渲染性能的优化
减少渲染中的重排重绘
浏览器重新渲染时,可能会从中间的任一步骤开始,直至渲染完成。因此,尽可能的缩短渲染路径,就可以获得更好的渲染性能。当浏览器重新绘制一帧的时候,一般需要经过布局、绘图和合成三个主要阶段。这三个阶段中,计算布局和绘图比较费时间,而合成需要的时间相对少一些。
以动画为例,如果使用 JS 的定时器来控制动画,可能就需要较多的修改布局和绘图的操作,一般有以下两种方法进行优化:
- 使用合适的网页分层技术:如使用多层 canvas,将动画背景,运动主体,次要物体分层,这样每一帧需要变化的就只是一个或部分合成层,而不是整个页面。
- 使用 CSS Transforms 和 Animations:它可以让浏览器仅仅使用合成器来合成所有的层就可以达到动画效果,而不需要重新计算布局,重新绘制图形。CSS Triggers 中仅触发 Composite 的属性就是最优的选择。
优化影响渲染的资源
在浏览器解析 HTML 的过程中,CSS 和 JS 都有可能对页面的渲染造成影响。优化方法包括以下几点:
- 关键 CSS 资源放在头部加载。
- JS 通常放在页面底部。
- 为 JS 添加 async 和 defer 属性。
- body 中尽量不要出现 CSS 和 JS。
- 为 img 指定宽高,避免图像加载完成后触发重排。
- 避免使用 table, iframe 等慢元素。原因是 table 会等到它的 dom 树全部生成后再一次性插入页面中;iframe 内资源的下载过程会阻塞父页面静态资源的下载及 css, dom 树的解析。
利用 GPU 硬件加速
css 中可以使用 gpu 加速渲染来减轻 cpu 压力,使得页面体验更流畅,默认 transform、opacity、filter 都会新建新的图层,交给 gpu 渲染。对于这样的元素可以使用 will-change: 属性名; 来告诉浏览器在最开始就把该元素放到新图层渲染。
显卡中集成了 gpu,提供了驱动,使用 gpu 能力需要使用驱动的 api。gpu 的 api 有一套开源标准叫做 opengl,有三百多个函数,用于各种图形的绘制。(在 windows 下有一套自己的标准叫做 DirectX)
我们在网页中绘制 3d 图形是使用 webgl 的 api,而浏览器在实现 webgl 的时候也是基于 opengl 的 api,最终会驱动 gpu 进行渲染。
css 大部分样式还是通过 cpu 来计算的,但 css 中也有一些 3d 的样式和动画的样式,计算这些样式同样有很多重复且大量的计算任务,可以交给 gpu 来跑。
浏览器在处理下面的 css 的时候,会使用 gpu 渲染:
- transform
- opacity
- filter
- will-change
浏览器是把内容分到不同的图层分别渲染的,最后合并到一起,而触发 gpu 渲染会新建一个图层,把该元素样式的计算交给 gpu。
opacity 需要改变每个像素的值,符合重复且大量的特点,会新建图层,交给 gpu 渲染。transform 是动画,每个样式值的计算也符合重复且大量的特点,也默认会使用 gpu 加速。同理 fiter 也是一样。
这里要注意的是 gpu 硬件加速是需要新建图层的,而把该元素移动到新图层是个耗时操作,界面可能会闪一下,所以最好提前做。will-change 就是提前告诉浏览器在一开始就把元素放到新的图层,方便后面用 gpu 渲染的时候,不需要做图层的新建。
当然,有的时候我们想强制触发硬件渲染,就可以通过上面的属性,比如
will-change: transform;
/* 或者 */
transform: translate3d(0, 0, 0);
chrome devtools 可以看到是 cpu 渲染还是 gpu 渲染,打开 rendering 面板,勾选 layer borders,会发现蓝色和黄色的框。蓝色的是 cpu 渲染的,而黄色的是 gpu 渲染的。
gpu 硬件加速能减轻 cpu 压力,使得渲染更流畅,但是也会增加内存的占用,对于 transform、opacity、filter 默认会开启硬件加速。其余情况,建议只在必要的时候用。